
 Hey—you’ll never guess what I’ve been up to!
Hey—you’ll never guess what I’ve been up to!
Give up?
I’ve been doing empirical analyses of park factors.
Obsessively. For weeks and weeks.
So far we’ve looked at how park factors do in predicting home park performance after players switch teams, and also how well park factors predict away performance in any given season. For the latter, we used both out-of-sample observational methods and quasi-experimental, propensity matching methods.
So far, it looks like park factors systematically miss the mark. A recurring problem is that they overstate the impact of differences in parks on batters’ wOBAs, the offensive-production metric used by leading systems for computing player WARs.
But as a practical matter, how consequential is this tendency to err? That’s what I am investigating now.
It’s actually the $1 million question (that’s not much, though: about the amount batters can make in a couple of dozen ABs, and pitchers in fewer than 100 throws). It’s the key to assessing the critical “park factor tradeoff.”
As discussed previously, park factors, if validly calibrated, can give us a better estimation of a batter’s “true ability” abstracted from the alternately inflationary and deflationary impact of playing in parks of different dimensions.
Knowing that is hugely important. It matters, certainly, if you are just a curious person who is interested in accurately comparing players. But it’s immensely consequential if you are involved in building a baseball roster, and are considering how much value acquiring a particular hitter will bring to your club. Or if you are a gambler trying to assess the prospects for particular players and teams as they migrate from stadium to stadium.
But park factors also come at a cost—one imposed on those very same evaluators. Adjusting a hitters’ wOBAs, say, based on their home-field park factors weakens the explanatory and predictive power of models fueled by measurement of players’ actual performances. This is necessarily true: the whole point of park factors is to flatten out differences in performance attributed to playing conditions; do that, and your estimate of the consequences of variance in performances will suffer—and not a trivial amount.
For park factors to pay for themselves, they must make a contribution to the sorts of practical decisions or evaluations they are designed for that’s big enough to compensate for the negative effect they have on the basic components of an analytical apparatus. So do they?
That’s the question I’m now starting to probe.
Consider this measurement of the average error of park factor forecasts as a first go.
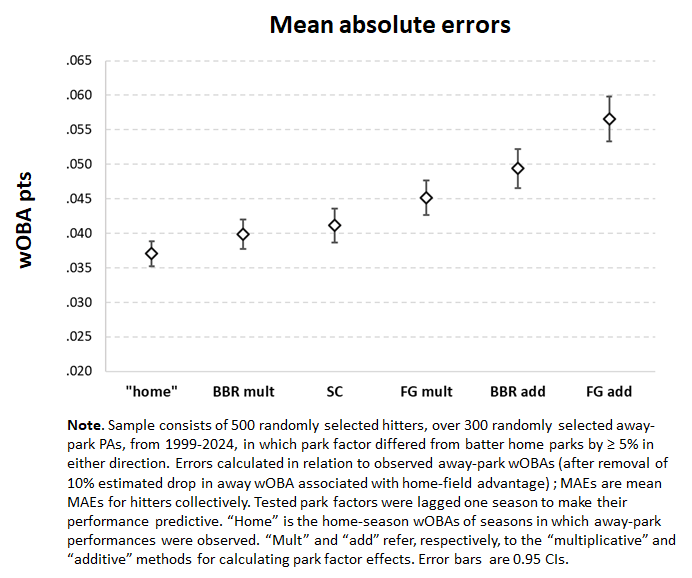
It reflects the performance of 500 randomly selected batters over 300 randomly selected away-park plate appearances. The plate appearances are ones in which the difference between the park factor of their home fields and those of the away ones in which they are hitting was at least 5% (e.g., a “95” or “105” park for someone who plays in a neutral, “100” one). It’s only when parks vary from the average by some appreciable amount that there’s anything to actually measure with park factors.
I extracted this data from records of every regular season plate appearance in major league baseball from 1999 to 2024. That’s over 4 million PAs by over 5,000 hitters! Using data this extensive and granular enables much more precise measurement of park-factor accuracy than ones based on team performances at home and on the road, the usual focus of assessment.
Park factors are structured in a manner that enables us to put performances recorded in diverse fields on a common scale. Every park’s factor, of course, reflects the margin by which performances in it are expected to deviate in percentage terms from performances in a “neutral” one, which is assigned a factor of 100. It follows that performances recorded in one park (h, say) can be made commensurable to ones in another (a) by multiplying performances in the former by the ratio of the latter’s and former’s respective park factors (pfa and pfh: park h performance * pfa:pfh = park a performance).
 So I applied that adjustment to every plate appearance outcome in my randomly selected sample. I imputed to each of those plate appearances a wOBA outcome equivalent to the player’s home wOBA multiplied by the ratio of the away stadium to his home stadium park factors.
So I applied that adjustment to every plate appearance outcome in my randomly selected sample. I imputed to each of those plate appearances a wOBA outcome equivalent to the player’s home wOBA multiplied by the ratio of the away stadium to his home stadium park factors.
When we average those imputed outcomes, they tell us the park-factor-adjusted wOBA to expect for performances over the sampled 300 road-park PAs. To assess the predictive accuracy of the park factor metrics, then, we can simply subtract that park-factor-adjusted expected road wOBA from the player’s actual road wOBA. Do that for 500 players, and you can calculate a robust mean absolute error subject to a standard error that helps assess the precision of that MAE.
(One qualifying detail: there really is a home-park advantage; others have shown it, and any empirical analysis of how park factors truly operate will confirm this conclusion. If you ignored that hitters do better at home, you would end up charging this generic negative effect on away-park wOBAs to park factors, biasing measurement of their accuracy. To avoid that, one has to “remove” the home-field advantage effect–basically by adding the wOBA points hitters lose to it on the road–before before calculating the difference between a player’s actual away wOBA and his expected pf-adjusted mark.)
I did all that for Statcast’s, FanGraphs, and Baseball Reference’s park factor systems, each of which was “lagged” a season to make this a measurement of the out-of-sample, predictive error of these competing pf sets. For Statcast, I used the “handedness” factors that it calculates to distinguish the impact of parks based on which side of the plate a batter hits from.
I also tallied the errors of a naïve predictor—namely, a player’s home wOBA. Obviously, it is absurd to believe that a road wOBA will truly be “equal” to a player’s home one notwithstanding changes in park dimensions. But in assessing the practical significance of tolerating park-factor error, this naïve “away=home” prediction furnishes an informative benchmark.
And what do we see? In fact, all of the park-factor perform worse than the naïve “away = home” benchmark! Yikes!
Note, too, that the away=home prediction didn’t do particularly well: an average error of 35 wOBA points, which is about the standard deviation in wOBAs measured over a season.
To make matters worse, this is the degree of error observed in about the number of PAs we’d expect of an everyday regular. Plenty of semi-regulars, particularly platoon players, will come to the plate fewer times than that, even if they are still important parts of a club’s offensive array. The average mean errors will be even bigger for them.
By the same token, the MAEs of the Statcast, FanGraphs, and Baseball Reference systems’’ errors would definitely shrink with even more PAs. They aren’t devoid of value; just noisy. But 5,000 or more PAs, say, is not a realistic depiction of the evaluation horizon of a practical decisionmaker; she cares most about this season or next, and is not impressed about arguments that take a “long run” view of park factors.
You’ll also note that the figure distinguishes between “multiplicative” and “additive” methods for computing both BBR’s and FG’s pfs. I’ve discussed the distinction before. Basically, the “additive” approach assigns the impact of a park to the park and dolls out its effect on a pro rata basis to individual players. For wOBA, this just means assigning a uniform wOBA-point discount to hitters, since the unit of performance output is simply a plate appearance.
This approach isn’t mathematically sound, frankly. Again, park factors reflect the ratio at which events occur in different parks, and thus have a bigger absolute impact as hitter’s performances (their production of those events) improve.
It’s not surprising to learn (or be reminded) that the additive approach is defective.
And it is just bizarre that this is how both BBR and FG incorporate park factors into their calculation of offensive WAR, which, as I said, turns on wOBA. They could easily remove a good fraction of the damage that their park factors are doing to their respective calculations by simply using the multiplicative approach—as the most sophisticated proponents of park factors do.
I’m not ready to say yet that I think that BBR’s and FG’s park factors—or SG’s, which definitely are better—are worse than nothing. Indeed, regression model estimates of how performances relate to these sets of park-factors effects have considerably smaller MAEs.
And “nothing” shouldn’t be what anyone settles for. I still am exploring what a better alternative might be. Here nobody—the naïve “away=home”—beat somebody, namely, the park factors of BBR, FG, and SC.
But there are a team of somebodyelses out there that definitely beat the naïve “away=home” position.
Stay tuned. . . .