
 I’m not dead yet (as far as I can tell)! Just deep, deep down (way more than 6′) inside the park factor rabbit hole. . . .
I’m not dead yet (as far as I can tell)! Just deep, deep down (way more than 6′) inside the park factor rabbit hole. . . .
In this installment of my reports, I will tell you about another empirical study of park-factor performance.
I will also introduce two new characters into this unfolding story: Ms. Sims and Mr. BLUP!
But start with the study.
As you I’m sure recall vividly, we’ve examined how well park factors predict away-park performance, both with an out-of-sample observational study and with a quasi-experimental propensity-matching one. The answer? Not very for the systems under examination—viz., those of Baseball Reference, FanGraphs, and Statcast.
Now we’re going to return to the question of how well pfs predict the impact of changing teams: do players’ home park performances—measured by their wOBAs—migrate as predicted by pfs?
Actually, you’ll recall (again, I’m sure) that we did this once already. In an earlier post I more-or-less replicated the findings of Bill Petti, who found that in such situations, pfs tend to overstate the impact of the move on power hitters.
But Petti’s study and my modest replication both focused on two seasons’ of results—the one immediately before and the one immediately after the switch.
A limitation of such a test is that wOBAs themselves are noisy. All the more so when the players whose performances are being examined might not have had a large number of PAs. Well, how can we be sure that the seeming predictive imperfection of pfs in such a test is not really just an artifact of the noise in the performance metric it is being tested on? Well?? Well???
Well to start, we can enlarge our sample!
In this test, I look not at performances across two consecutive seasons but two consecutive team stints. I examined performances of players across the entirety of their time with one team and then across the entirety of another. I did that for 425 players who went from one club to another over the course of the 1998 to 2024 seasons.
I limited myself to players who had at least 500 PAs for their two home teams (about 1.67 seasons for a regular). But many of the players had many more than that.
For each player, I calculated the PA-weighted average of his home team park factor during his stint with each team. I then simply looked at how closely his home park wOBA in the second stint compared to what you’d expect it to be given the ratio of the new home park pf to the old one.
For both stints, by the way, I recalculated player wOBAs based on a single set of representative weights. wOBA weights get slightly adjusted every season, and we don’t want to be comparing wOBA sushi to wOBA sashimi.
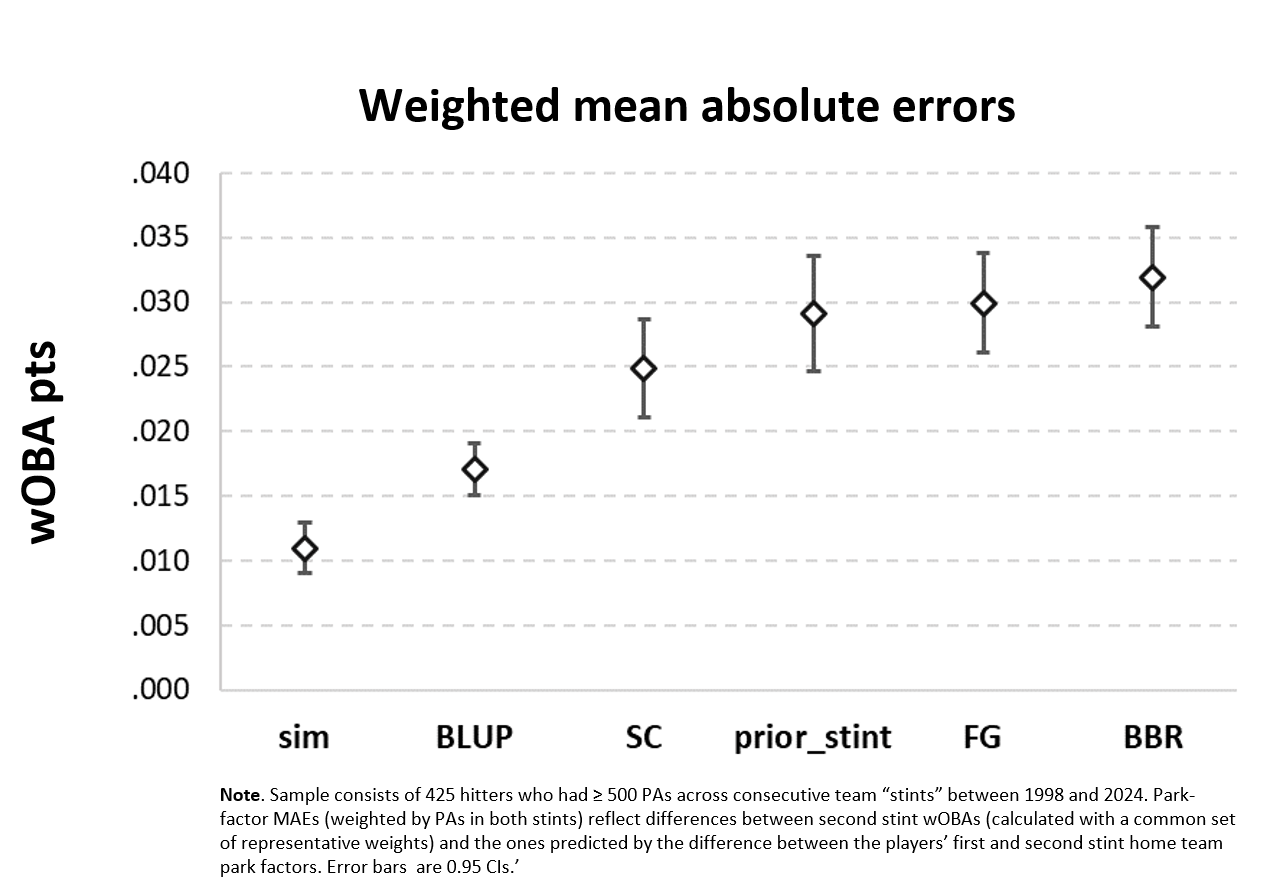
You can see that the pf predictions were off by about 25-30 wOBA pts & change. (Oh, and you can also see what the error distributions look like; this is a recurring pattern too—SC’s factors in particular are biased on the impact of batting in supposedly low pf, hitter-unfriendly parks.)
How good or bad is that? Maybe that’s still just wOBA noise?
That’s where Ms. Sim can help us!
Ms. Sim is a professional pf Monte Carlo simulator.
You start by furnishing her with the plate appearance wOBA outcomes of 1,000 randomly selected real players over some specified number of randomly selected PAs (here I chose 800, the mean number for stints in the sample). These are treated as the “home park” performances of those players, who are assigned randomly to a home park with a corresponding park factor.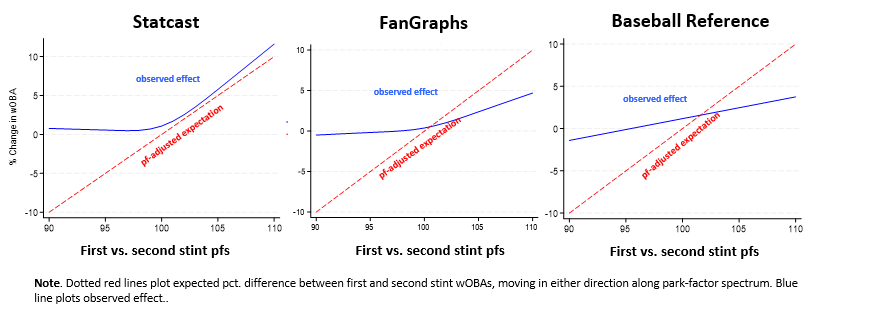
Ms. Sim simulates an equal number of performances across a specified number of away parks, each of which also has a park factor of its own. To do this, she simply adjusts upward the relevant hitter’s individual probability of each wOBA event (an out, a BB, an HBP, a single, a double, a triple, or an HR) by the ratio of the away park pf to the home one. That’s exactly how much park-specific impact park factors are supposed to reflect.
The stochastic part of the simulation, naturally, is the manner in which the away wOBA outcomes are determined. Basically, Ms. Sim arrays the probabilities of the various wOBA outcomes along a continuous line between 0 and 1 with each occupying a space equal in length to its individual probability. After that, Ms. Sim randomly selects a number between 0 and 1; whichever wOBA outcome occupies the corresponding space on the probability line is the player’s outcome for that PA!
Aggregate the 1000 players’ simulated performances across all of their 800 away PAs and this process is guaranteed (or double your money back from Ms. Sim) to generate the pf-adjusted away wOBA the player is supposed to have subject to the amount of random noise associated with wOBA performances!
Then we simply compare these simulated away wOBAs to the park-factor adjusted forecasts based on the players’ home wOBAs.
 The average difference between the two represents an upper-bound, essentially, on how well a perfectly-calibrated pf system should be expected to perform. The system wouldn’t be perfect—because wOBAs themselves inject noise into the outcomes. But the amount of error associated with that noise is now observable. We can judge the performance of a real pf system in relation to the error reflected in that outcome and not worry that we are “penalizing” the pf system’s performance for error that really is a consequence of the unavoidable wOBA wobble associated with however many PAs are being simulated.
The average difference between the two represents an upper-bound, essentially, on how well a perfectly-calibrated pf system should be expected to perform. The system wouldn’t be perfect—because wOBAs themselves inject noise into the outcomes. But the amount of error associated with that noise is now observable. We can judge the performance of a real pf system in relation to the error reflected in that outcome and not worry that we are “penalizing” the pf system’s performance for error that really is a consequence of the unavoidable wOBA wobble associated with however many PAs are being simulated.
Now in the study I performed, pfs were being tested not for how well they predict away wOBAs in a particular season but rather for how well they predict home wOBAs across them in a subsequent team stint.
No problem! I explained all this to Ms. Sim, and all she had to do, after being fed the real PA performances of the randomly selected 1,000 players, was assign each one randomly to a single new home park. Then she used that new park’s pf when simulating the second stint PAs. Aggregate—and there you go, a simulated park-factor adjusted second stint incorporating the correct quantum of wOBA noise!
I have a real crush on Ms. Sim!
Now we see that the expected “error” associated with perfectly calibrated pfs is about 11 wOBA points.
That’s less than 25-32, obviously. So how bad is that really? “You can’t beat somebody with nobody,” right?
Well, actually, it’s possible you could. Just predict that the player would have the same wOBA in the second stint as he did in the first—forget pfs! That strategy proved better in the home-away out-of-sample test, and it would do pretty well here, generating a more accurate prediction than every pf system excepts Statcast’s, to which it would lose by a practically nonsignificant amount.
But now meet Mr. BLUP!
Mr. BLUP is also known as “Best Linear Unbiased Prediction.” He has been working for years in the cattle-breeding industry but loves baseball (the balls are made of cowhide, right? Gloves too!).
His specialty is identifying how individual differences—latent characteristics like the genetic predispositions of cows —can be abstracted from other conditions that generate variance. Such situations (what farmers feed their cows, climatic differences among farms, the music played to put cows in the mood to mate) can obscure the role that the latent disposition has.
But really, Mr. BLUP is not relying on super powers. He uses (or just is) each observation’s (cow’s) random intercept plus grand mean when you run a multi-level regression.
Well, we can do that here. Just fit a simple random-intercept model and extract every MLB player’s BLUP. In fact, Mr. BLUP did just that 26 times—starting with the 1998 season and then adding a season (1998 and 1999; 1998, 1999, and 2000, etc.) to each successive model. BLUP estimates improve as data accumulates. But by coming up with 26 progressively enlarging sets of BLUPs, we can see what any hitter’s BLUP was at the beginning of any season. Which, of course, is when it matters as a potential influence for prediction of player performance.
So Mr. BLUP decided to see if the Best Linear Unbiased Prediction he formed for each player at the end of one stint could better predict that player’s next stint home-park wOBA more accurately than a park-factor driven prediction system would.
And it turned out that Mr. BLUP’s predictions were better than all of them—BBR’s, FG’s, and SC’s! (Ms. Sim was smitten; damn . . . .)
Now Mr. BLUP’s predictions didn’t match the results of Ms. Sim’s “park factor best case” sim.
But because he did do substantially better than any of the park-factor systems actually in use, we can now confidently say that the gap between those systems and Ms. Sim’s prediction is bigger than anyone should treat as acceptable.
Why?
 Because you could form better predictions by ignoring those real-world park factors and relying instead on players’ BLUPs!
Because you could form better predictions by ignoring those real-world park factors and relying instead on players’ BLUPs!
Mr. BLUP is our “somebody” benchmark, then, when we evaluate the gap between park factors as they are and park factors as they ideally could be (Ms. Sim’s tally). We can’t expect park factors to be perfect; but we can insist, before using them, that they be better than any available park-factor independent alternative.
BTW, I know what you are thinking: that the successive-stint test is ignoring all sorts of things—like aging, most importantly—that will affect how second stints compare to first ones.
That’s for sure true. But it’s not important for our purposes.
We could account for aging, for example, with whatever age-profile adjustment we think is best. And do the same for any other thing we think matters as players’ careers progress.
But we could—should—do that whether we used a park-factor adjusted model or some park-factor independent one to predict how migrating from one home park to another will affect a hitter’s performance.
So as between those approaches—park factors or no—those other considerations are a wash. They are ignorable, because even after adding them in, the difference between Mr. BLUP’s prediction, say, and the park factors will remain.
And just so you know, we’re seeing a very unambitious side of Mr. BLUP! Ideally, we should add fixed effects to make the random intercept estimates more precise, and to improve our prediction by accounting for other skill-independent influences a player will face (that is, influences that are non-random with respect to players of different latent abilities).
So that’s where I’m at, down here in the hole! Seeing lots of cool things and making new friends!
I might never go back up!