
 Here’s a bit more on how the empirical fielding-independent pitcher metric—eFIP— compares with Baseball Reference’s and Fangraphs’s pitching-runs saved measures.
Here’s a bit more on how the empirical fielding-independent pitcher metric—eFIP— compares with Baseball Reference’s and Fangraphs’s pitching-runs saved measures.
I’ve previously shown that eFIP does a better job in out-of-sample predictions, which is an important feature of a valid estimator of pitcher latent skill—a measure of an inherent ability level.
But here I’ll just look at in-sample performance. That matters to the extent that one considers a metric like WAR a kind of season-specific accounting summary of the contribution that a player made to his team’s record.
Using a sample consisting of every AL/NL season from 1900 to 2025, I regressed team total runs allowed on team fielding-runs saved. That’s a control variable, which establishes a benchmark or baseline. Then I did three more regressions, which added BBR’s pitching runs-saved measure, FG’s, and the eFIP-derived one, respectively. That way we can see how much incremental explanatory power (measured in R2, which is proportion of variance explained) each has for team runs allowed.
Here’s the result:
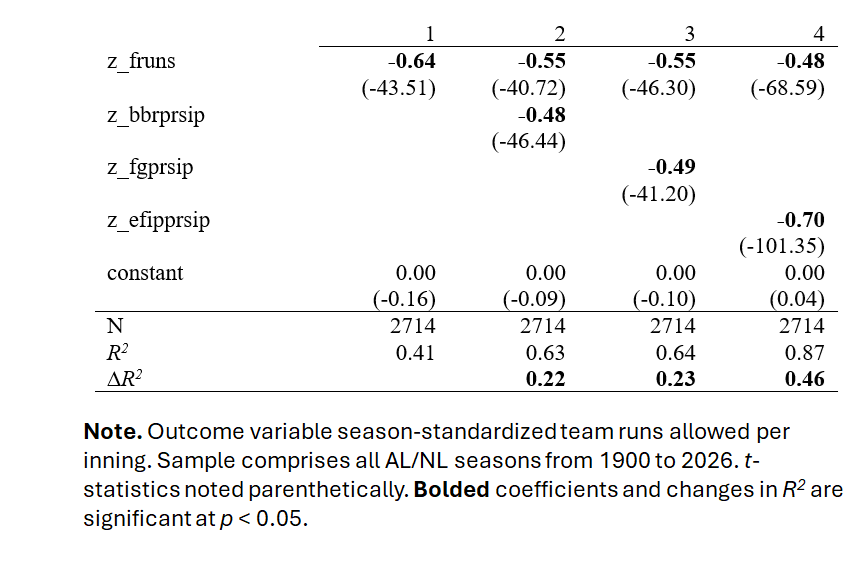
There are some more details on how the measures were formed in the notes below. But the bottom line is that, relative to both BBR’s and FG’s pitching-runs saved measures, eFIP accounts for double the amount of variance in team runs allowed per season after accounting for team fielding-runs saved.
That’s huge.
This analysis fits a single model to all of AL/NL history, using variables appropriately scaled to remove any “era” effects not related to differences in the quality of teams’ pitchers. Again, see the notes below for details on that.
But it is also possible (and more entertaining) to do the analysis season by season:
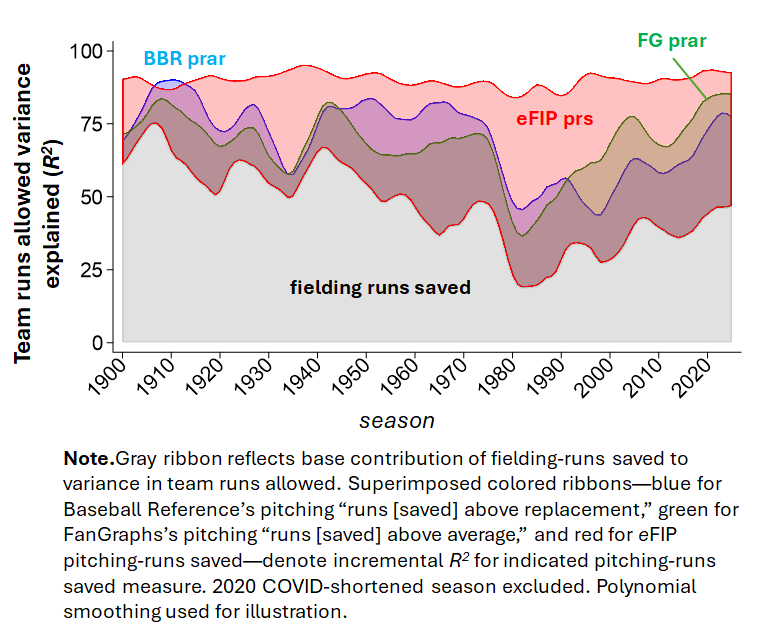
It’s clear that the eFIP/fielding-runs saved combo does a great job accounting for variance in team-runs scored. They are consistently explaining the lion’s share of the differences in team runs over the course of AL/NL history
Interestingly, BBR briefly attained king-of-the-hill/mound status for a tiny bubble of seasons around 1910. But what we see for the most part are that the BBR and FG pitching-runs saved measured bouncing up and down a lot over time, trading places with one another a couple times—but both far behind the eFIP measure. Beats me why BBR’s and FG’s measures were so volatile, although they frequently shared big downslides, suggesting they both were missing the same thing about pitcher value at the same time. . . . Interesting!
Moral of the story, though, is that if one wants to form accurate season-value summary assessments of pitcher value of the sort that figure in pitcher WAR, then eFIP is much better than BBR’s and FG’s measure.

Method notes:
- I used the BBR’s and FG’s “pitcher-runs [saved] above replacement,” rather than “above average,” because that’s all one can get from FG’s team-stats pages. For regression purposes, though, the only difference between “above average” and “above replacement” is the intercept: 0, when the reference is the number of runs saved by an average MLB pitcher; and some number arbitrarily greater than 0 when the reference is the runs saved by a “replacement.” The covariance with total team runs allowed is unaffected, and hence so is the regression estimate of teams’ pitcher contributions to differences in team runs allowed.
- I used the composite fielding-runs saved measure that earlier site research on “rfield inflation” (published since in the Journal of Sports Analytics) demonstrated has the largest impact on variance explained for team runs allowed.
- I divided team the variables for team runs allowed, team fielding-runs saved, and team pitching-runs saved by each team’s innings pitched—so that in-season differences related to how many innings teams’ pitchers happened to throw would not affect the result.
- I also season-standardized all the variables so that changes in “run environment” and other era-specific influences unrelated to relative pitcher value would not obscure the contribution of differences in team pitching performances to differences in team runs allowed. As the 40,323,876 regular readers of this blog know, this technique puts historical measures of performance on a common scale.
I’ve uploaded the data and code necessary to reproduce these analyses to the library—enjoy!