
 It’s way past time to move on–I know, I know!
It’s way past time to move on–I know, I know!
But I wanted to add just one more piece to the fielding-measurement picture: the performance of Ultimate Zone Rating, or UZR.
I realize now that what I’ve said up to this point might make it look I’m talking only about how Baseball Reference (BBR) computes the fielding component of WAR.
So let’s expand the focus a bit.
First of all, let’s consider the difference between how FanGraphs and BBR measure the fielding component of WAR. There isn’t much up to 2002. Up until then, they both use as the basis of their formulas Sean Smith’s Total Zone Ratings. Accordingly, they both do a great job in picking up the substantial amount that fielding contributed to averting runs throughout most of the 20th century. They do both suffer, however, from the 1990s lacuna, when TZR was informed by a less reliable component of retrosheets (viz., the data associated with its “Project Scoresheet”; Smith discusses this in War in Pieces).
Using TZR, they also both capture the early stage of the surge of field-independent pitching or FIP, and how it started to reduce the practical importance of fielding beginning sometime around 1990 (maybe a bit before, actually) into the early 2000s.
Call this the “fielding shrinkage” effect.
FanGraphs switched to Ultimate Zone Rating after 2001, and BBR to Fielding Bible’s Defense Runs Saved after 2002. Both UZR and DRS make use of digital information supplied by Baseball Info Solutions.
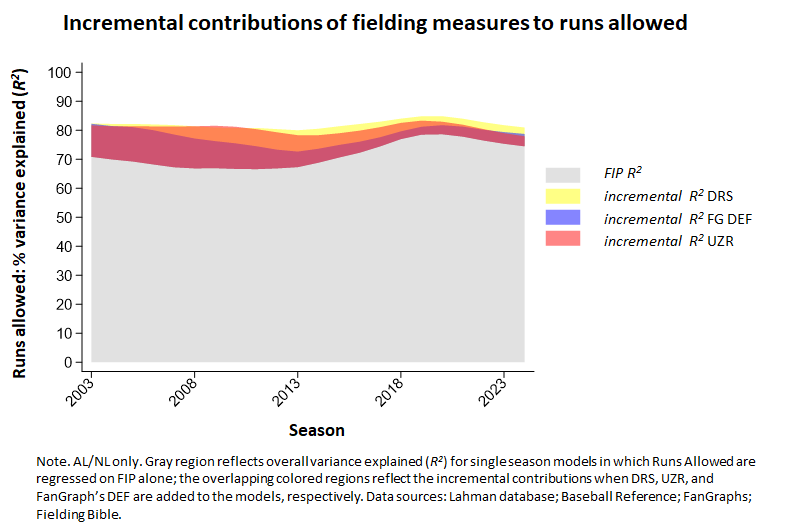
Both UZR and DRS report the continuing and expanding impact of fielding shrinkage. With these respective measures, FanGraphs and BBR are both trying to find out how much difference fielding make after taking account of the whopping 70-75% of variance explained that FIP contributes to measurement of team runs allowed.
 It turns out that DRS captures a little bit more of that residual than DRS. But the difference isn’t that big: about 8% of variance explained for UZR vs. 10% for DRS since 2003. (FG’s “DEF” measure, which uses a “position” adjustment for UZR as it figures in its computation of WAR, actually explains less: 5%.)
It turns out that DRS captures a little bit more of that residual than DRS. But the difference isn’t that big: about 8% of variance explained for UZR vs. 10% for DRS since 2003. (FG’s “DEF” measure, which uses a “position” adjustment for UZR as it figures in its computation of WAR, actually explains less: 5%.)
It would be pretty hard for either DRS or UZR to explain much more given how dominant FIP is; because statistical noise is a fact of life, it’s really impressive to for the combined effect of FIP and either of these fielding measures to be approaching as much sd 85% variance explained, and indeed anything higher would be almost unthinkable (short of the substitution of measures that were derived in a manner guaranteed to be overfitting the data).
But there is one really cool thing to add: the impact of UZR on what I’ve called “rfield inflation.”
Rfield inflation refers to the progressively increasing degree to which BBR’s rfield measure overstates the run-saved effect of differences in fielding. This effect isn’t entailed by fielding shrinkage; it is a consequence of failing to recalibrate the measure of fielding proficiency’s relationship to runs saved as fielding has declined in importance relative to pitching.
Proving that fielding shrinkage and rfield inflation are different, UZR, it turns out, displays something much closer to an honest measure of the impact of differences in fielding proficiency. That is, on a team level, it’\s certification of a run saved (or cost) as a result of fielding proficiency comes closer to measuring a one-run impact than does DRS, which in recent seasons has overvalued the impact of fielding by a fact of two. (Note again, though, that FanGraph’s adjusted “DEF” measure seems to be cancelling out this really nice feature of UZR.)
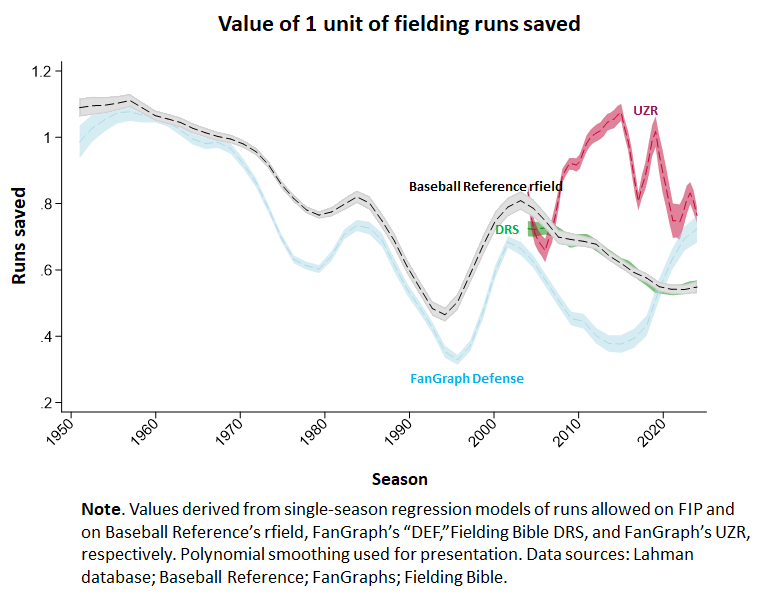
The relationship between a unit of UZR and a one-unit increment in actual runs allowed jiggles about a bit, but that’s an inevitable consequence, too, of the limits of statistical measurement precision, and should cancel out over the course of a reasonable number of seasons.
But again, the success of UZR in avoiding rfield inflation is not a consequence of it being a better measure of fielding proficiency than DRS. It’s actually a bit weaker, as I noted (but the difference is truly negligible).
What UZR is doing better is mapping the units in which it measures fielding proficiency onto actual runs saved. That’s really great. And there’s no reason that DRS can’t be recalibrated to do the same. That would be great, too!
Okay—I swear that’s it! I’m climbing back into BABIP hole. . . .
I’ve added the UZR data to the data library.