
Download it here. Just a draft, so looking for feedback! Will put up dataset & codebook in due course, but if you head over to data library, all the data are there; analyses have been refined/extended but if you’ve been following along with the posts, you shouldn’t have trouble reconstructing them.

2 Responses
1. As you yourself note at end of pg 3 into pg 4, the runs-allowed variance explained simply by pairing FIP with these fielding metrics is remarkable!!! Did you try adding any other measures that might be thought to explain runs-allowed variance, such as (batting) strength of schedule?
2. Does the remarkable ‘explanatory advantage’ as you put it of DER give you any pause? Do you have concerns about retro-fitting, or have you done any data-quality analysis of DER?
These are good questions.
1. I don’t think quality of opposition and schedules are important in these models. There’s so much data, being looked at over such a long period, that those factors will all cancel out. Trying to take account of unbalanced schedules and opponent strength is much more important if you are trying to handicap individual match ups. And obviously, it’s a lot worse in sports that feature shorter &/or unbalanced schedules. That’s a huge challenge for football definitely.
2. DER is definity not derived after-the-fact from runs scored. You can find most of the details in Smith’s book, but basically, he is just treating any ball hit in play as a fielding opportunity for a proximate fielder (sometimes assigning fractions of an opportunity to multiple fielders–or at least that is how TZR works) & then tallying the proportion of those turned into outs. Those ratios can be used to determine the relative proficiency of players at given positions. I’m not sure, though, how he converts those ratios into “runs saved”–that’s the calibration issue discussed in the paper (which isn’t as big for DER as it is for TZR and DRS, e.g.). Be a great thing to find out. One super important thing you won’t find in the book, unfortunately, is coding method he uses to turn retrosheet “events” into player fielding opportunities. You’d need that to replicate, refine, extend the measure etc. You could try to develop such a code yourself—but believe me, it’s a *huge* endeavor!
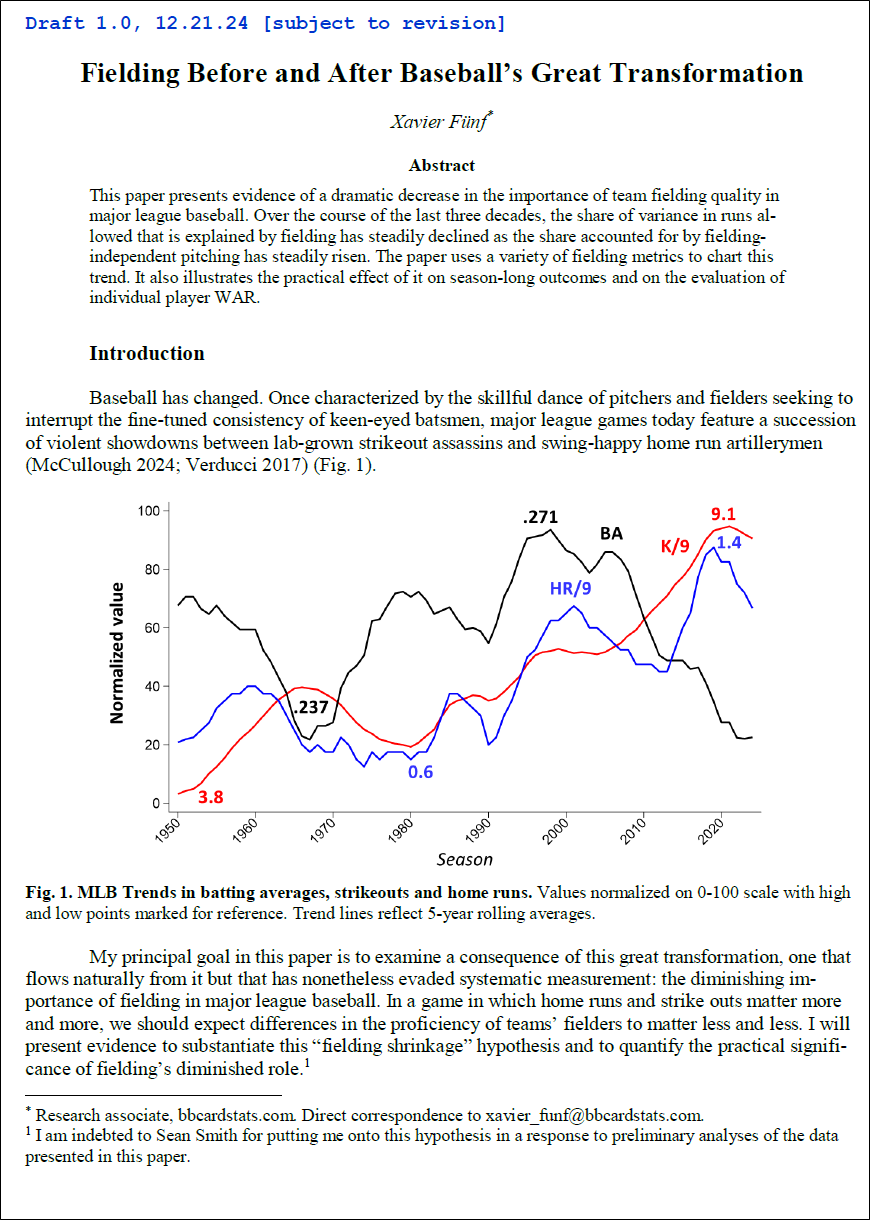
3. I agree with your observation that the amount of variance explained by FIP plus TZR/DER or even FIP plus DRS is astonishing. FIP itself is a monster; that it can explain 75% of the variance by itself nowadays is mind-boggling. BTW, OPS is a monster too. These aren’t the sorts of R^2s that anyone who sudies outcomes in labs, in nature, in neighborhoods, in test-taking rooms etc. expects to see. Particularly given how parsimonious the models are (it’s easy to jack up an R^2 by pouring in gallons of variables)… But another thing that shocks me is as far as I’ve been able to determine, it’s always been the most consequential pitching-related metric for explaining team runs allowed—which is crazy considering how the frequency of both strikeouts & homeruns has surged in recent decades. . . I’d love to be able to find some other explanation for pitching success in 1930s, 1950s etc. Maybe you can do it!