
 One cool element of the “mWAR Estimator” is that it is customizable to user preferences.
One cool element of the “mWAR Estimator” is that it is customizable to user preferences.
Say the user was someone who was trying to decide whether to retain or hire a new manager. What preferences might this user have other than to identify who the “most skilled” available manager is?
The answer is that he or she would likely have additional, more complex preferences relating to risk and uncertainty.
The uncertainty inheres in the estimation process. The Estimator always learns more about the population of managers as it trundles along than it does about individual managers. Accordingly, it will identify fewer individual managers that it can confidently declare possess a particular level of proficiency—say ± 2 wins per 162 games (the mw162 mode of the Estimator’s scoring system)—than it can confidently say exist in the pool of prospective managers generally.
Only about 10% of managers can be identified by the Estimator has possessing a so-called MAP—or maximum a posteriori or most probable estimated value—of |mw162| ≥ 2.0. But because the Estimator is able to determine that there are many who have a non-zero probability of that level of proficiency, it can also estimate a population level incidence of it. That turns out to be 40%!
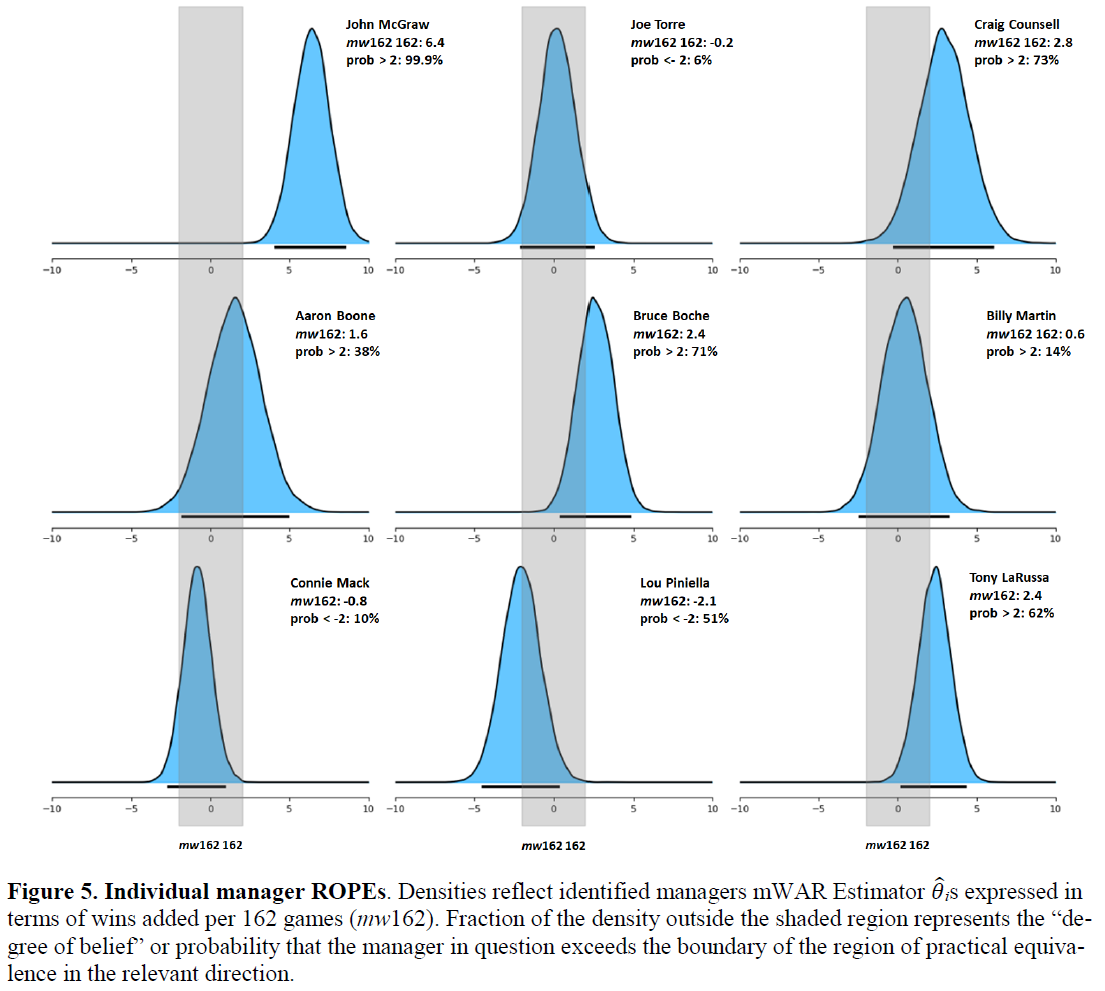
This is a feature of the Estimator’s Bayesian information-processing design. The Estimator has to update its initial assumption about manger skill (assumed to be zero at the start of one’s career) every season—and every season it learns 30x as much about managers in general as it learns about any one of them. Indeed, even when it concludes that a manger is, say an mw162 +2, it takes it about 6 seasons to figure that out!
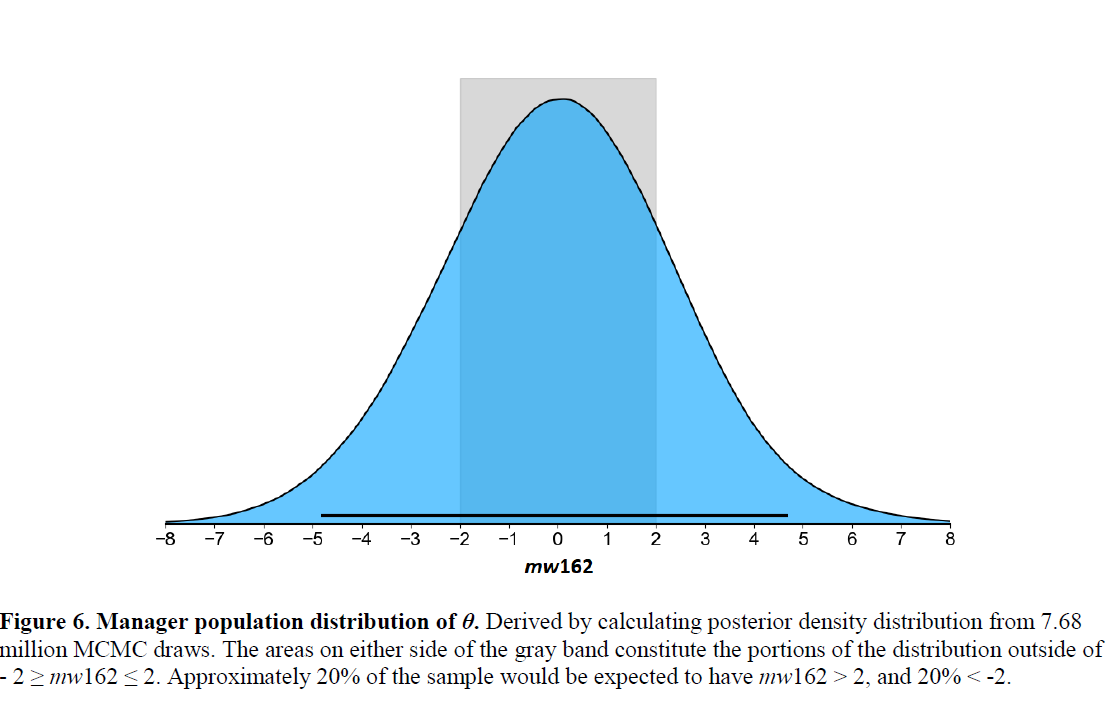
If you want to go out and get your team a “good” manager and avoid a “lemon” (or even a Bob Lemon—mw162 = 0.1), you have to face some uncertainty. There are a few bona fide great managers out there (very few) and a few bona fide boners. But you know there are rich, unexplored veins of talent—and ineptitude—around the +2 and -2 thresholds. And you can’t wait 1000 games to try to figure all this out.
That means you have to gamble a bit.
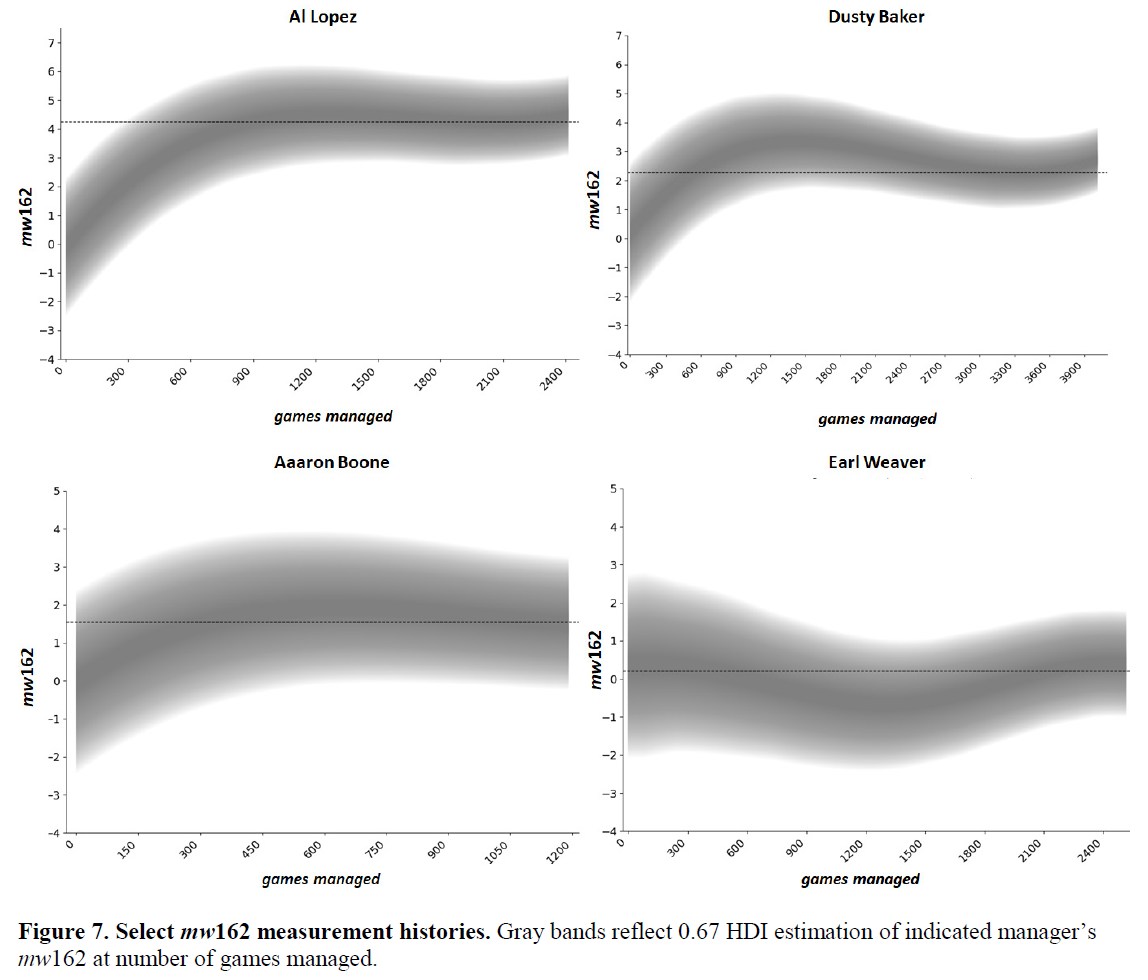
The Estimator understands this. And if you tell it about your risk preferences, it will recommend the best way forward.
The structure of baseball economics actually shapes these preferences in a fairly standard way. MLB uses what is called a “tournament structure” payout system, which means that select winners enjoy super returns. Those are the teams that make the playoffs, whose revenues are multiplied substantially.
In these kinds of markets, actors tend to be risk preferring with respect to potential gains and risk averse with respect to potential losses. That is, they’ll take a flier on a seemingly average opportunity that nevertheless has a small probability of a large upside, but avoid like COVID 19 an opportunity that seems generally okay but has a small probability of a large downside. Even small bits of information can tip uncertain investment opportunities into one category or the other.
Consider how this would work in the “manager market.” There a prospective manager buyer—a front office or owner—is likely to act rapidly to get rid of a manager who gets off to a slow start. That manager might, if he turns out to be as bad as early signs suggest, cost the team a valuable playoff appearance. Of course, the buyer could be mistaken to view the manager as a loser. But if so, then the most probable truth about him was that he was average—since the decided majority of managers are. Anybody the buyer replaces him with will also likely turn out to be average. So hanging on to a bad manager too long is a disaster (possibly profit-destroying losses) compared to getting rid of a potentially okay manager too soon (meh). Risk aversion, in other words, with respect to a losing manager results in teams showing disappointing ones the door very quickly.
 On the other side, a front office is likely to cut a lot more slack to a manager who is not yet rocketing to the top but still doing okay. It takes a while for genius to reveal itself in his position. If he is a great manager, getting rid of him prematurely is awful—you let go of a vary hard to find and valuable asset! But if you hold on too long—no big deal: most likely he will reveal himself to be average (that’s what the vast majority of manager’s are), and average is exactly what the value of any replacement would likely be. So a team will be risk preferring—with good reason—toward a potentially superior manager: it will ride it out in the hopes that he is the next John McGraw.
On the other side, a front office is likely to cut a lot more slack to a manager who is not yet rocketing to the top but still doing okay. It takes a while for genius to reveal itself in his position. If he is a great manager, getting rid of him prematurely is awful—you let go of a vary hard to find and valuable asset! But if you hold on too long—no big deal: most likely he will reveal himself to be average (that’s what the vast majority of manager’s are), and average is exactly what the value of any replacement would likely be. So a team will be risk preferring—with good reason—toward a potentially superior manager: it will ride it out in the hopes that he is the next John McGraw.
BTW, front offices that behave this way will be reacting exactly the way corporate boards do in CEO retention decisions: economists have established that boards react much more quickly to signs of bad performance in a CEO than to signs that a CEO is not performing as well as the industry’s best. It’s a rational—that is to say, profit-maximizing—stance for boards to adopt in the face of uncertainty in a lot of industries.
Well, the mWAR Estimator can be programmed to implement exactly this risk-preference schedule.
Say, for the reasons that I’ve described, a team is 2x more averse to mistakenly concluding a manager possesses an mwWAR 162 ≥ -2 when in fact his mwWAR 162 < -2 than it is to mistakenly concluding he possesses an mwWAR 162 < -2 when in fact he possesses one ≥ -2. That is, they strongly prefer the error of underrating a potential loser to the error of overrating him. And by the same token, the team really dislikes underrating a possible winning manager much more than they dislike overrating him: the team is 2x as averse to mistakenly concluding a manager possesses an mwWAR 162 < +2 when in fact he possesses an mwWAR 162 ≥ +2 than it is to mistakenly concluding he possesses an mwWAR 162 ≥ 2 when in fact he possesses one < + 2.
If you plug these asymmetric preferences into the Estimator, it will recalculate the mw162 of every manager, replacing his MAP estimate with a loss-adjusted one that minimizes the specified error costs of hiring or retaining any particular manager.
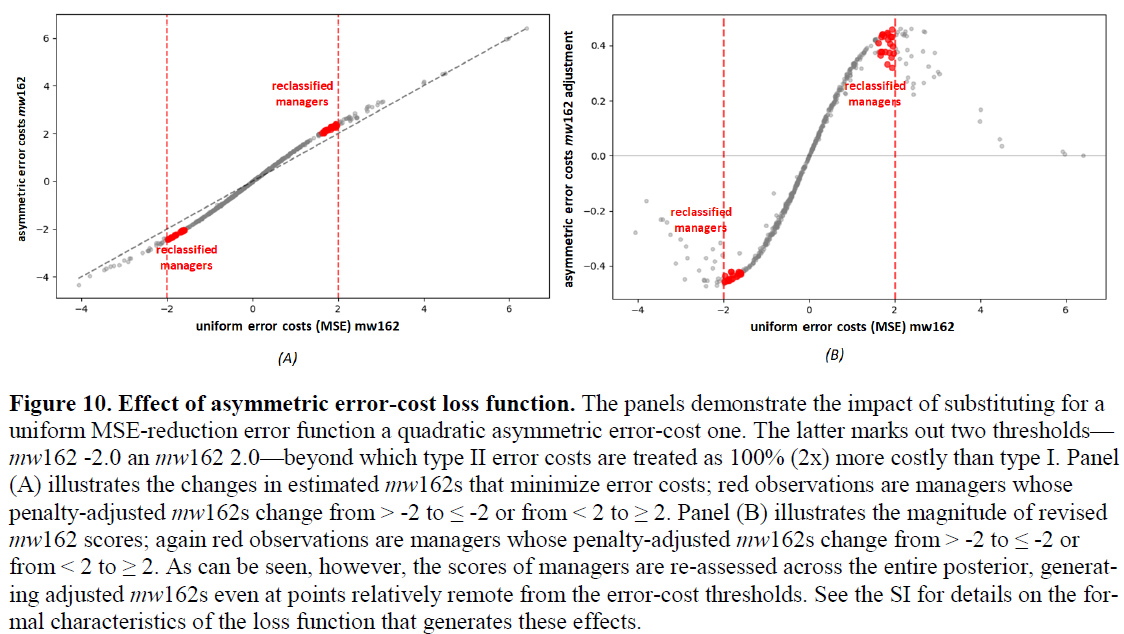
Pretty nifty!
But obviously, not everyone is using the Estimator to hire or fire a manager. Those who enjoy historical comparisons, for example, will likely stick with the “maximum accuracy” (minimum Mean Squared Error) default estimations. These users are in it for the long haul, and are less bothered by the Estimator’s deliberate learning curve.
They will still have to contend, though, with the discrepancy between what the Estimator knows about individual managers and what it knows about the manager population.
But there’s something the Estimator can help them do to mitigate this feature of its Bayesian updating speed, too.
I’ll tell you what the next time I post something.