
 Here’s a strange one: does team slugging percentage predict deviation from a team’s Pythagorean Expectation Formula (PEF() winning percentage?
Here’s a strange one: does team slugging percentage predict deviation from a team’s Pythagorean Expectation Formula (PEF() winning percentage?
There’s absolutely zero reason to believe it would in theory.
PEF, of course, predicts WP (really really well) based on runs scored and allowed. Slugging percentage generates runs. Why wouldn’t the impact of slugging already be accounted for in PEF?
Mathematically, PEF deviation depends entirely on a team’s run scoring distribution. If it “beats” its expectation, necessarily it has a smoother, low-variance distribution, which naturally “conserves” runs for wins in close games. If it is “beaten” by PEF, that necessarily means it had a more uneven, high-variance distribution and thus wasted in blowouts runs it should have saved up for those 1- or 2-run contests.
It’s plausible that a good manager helps a team eke out a few extra close wins. Or a good closer.
But there is no reason—zilch—to think that good slugging helps a team win more close games, as opposed to just more games.
Yet at least one commentator purports to claim otherwise.
 He says that there is a correlation between slugging and close wins and then purports to show in a toy simulation (not involving real teams or real data) that higher slugging means more wins than PEF predicts.
He says that there is a correlation between slugging and close wins and then purports to show in a toy simulation (not involving real teams or real data) that higher slugging means more wins than PEF predicts.
But if this is right, the way to show it is not with a toy simulation but a genuine empirical test.
Having done PEF-deviation testing recently on managers and bullpens, I added slugging to the lineup.
This time I used an empirical null technique involving “permutation”:
(1) Start by predicting the WP of teams based on a model that uses PEF and slugging.
(2) Collect the “residuals”—the differences between predicted and actual winning percentage points. Obviously, the lower the residual, the better the fit.
(3) Then permute—or randomly shuffle—the residuals across the teams. Do it by season: that way, the “run environment” and related shifting conditions unrelated to slugging’s impact on winning percentage are held constant across the teams whose winning-percentage residuals are being randomly re-assigned.
After (3), one has an “empirical null”: a collection of teams whose deviations from their PEF-residuals have been randomly assigned in a manner that—deliberately—bears zero relationship to their slugging percentages.
Then we just compare the rate at which teams exceeded their PEF-expected WPs in the “real world” or observed sample (where teams’ WP residuals and slugging percentages are intact) to the rate at which teams did so in the empirical null, where we know that slugging had no impact.
The result?
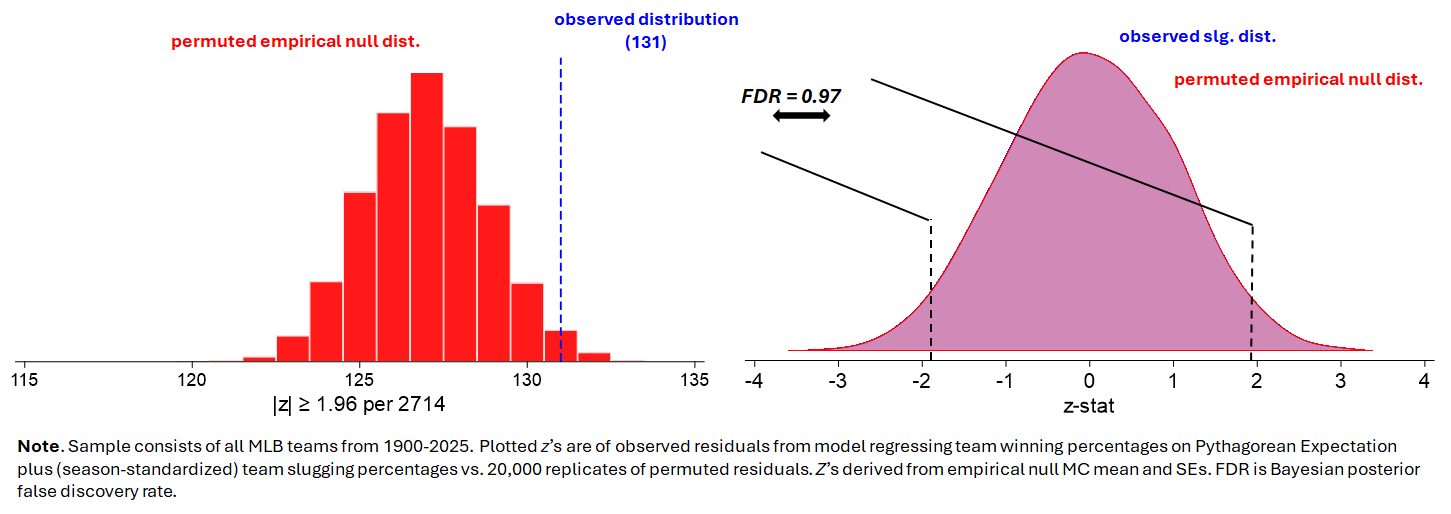
Slugging, as one would have surmised using common sense, has no meaningful impact.

Across the 20,000 simulations, the Bayesian posterior of a non-chance “extreme” (|z| ≥ 1.96) deviation from the PEF-predicting WP is about 3%. It can also be shown that the entire difference in residuals between the observed and null far short of the inherent noise associated with PEF attributable to the random, team-specific fluctuations in any level of run-scoring variation.
There’s just no there there.
So that’s three strikes—manager skill, bullpen/closer quality, and team slugging—against the practice of PEF as a benchmark for measuring the impact of one or another element of team composition.
None of this means that these features of an MLB team make no difference to team records. They all do!
It means that deviation from PEF-predicted winning percentage just isn’t a valid way to show that.